

Invatarea profunda este un domeniu cu cerinte de calcul intense, iar alegerea GPU-ului dvs. va determina in mod fundamental experienta dvs. de invatare profunda. Dar ce caracteristici sunt importante daca doriti sa cumparati un nou GPU? RAM GPU, nuclee, nuclee tensor, cache? Cum sa faci o alegere eficienta din punct de vedere al costurilor? Aceasta postare de blog va aborda aceste intrebari, va aborda conceptiile gresite comune, va va oferi o intelegere intuitiva a modului in care sa va ganditi la GPU-uri si va va oferi sfaturi, care va vor ajuta sa faceti o alegere potrivita pentru dvs.
Aceasta postare de blog este conceputa pentru a va oferi diferite niveluri de intelegere a GPU-urilor si a noilor GPU-uri din seria Ampere de la NVIDIA. Aveti de ales: (1) Daca nu sunteti interesat de detaliile despre modul in care functioneaza GPU-urile, ce face un GPU mai rapid in comparatie cu un procesor si ce este unic la noua serie NVIDIA RTX 40 Ampere, puteti sari direct la diagramele de performanta si performanta pe dolar si sectiunea de recomandari. Numerele cost/performanta formeaza nucleul postarii pe blog, iar continutul din jurul acestuia explica detaliile despre ceea ce alcatuieste performanta GPU-ului.
(2) Daca va faceti griji cu privire la intrebari specifice, am raspuns si am abordat cele mai frecvente intrebari si conceptii gresite in partea ulterioara a postarii pe blog.
(3) Daca doriti sa intelegeti in profunzime modul in care functioneaza GPU-urile, cache-urile si Tensor Cores, cel mai bine este sa cititi articolul de pe blog de la inceput pana la sfarsit. Poate doriti sa sariti peste o sectiune sau doua, pe baza intelegerii dvs. a subiectelor prezentate.
Prezentare generala
Aceasta postare de blog este structurata in felul urmator. In primul rand, voi explica ce face un GPU rapid. Voi discuta despre CPU vs GPU, Tensor Cores, latimea de banda a memoriei si ierarhia memoriei GPU-urilor si modul in care acestea se leaga de performanta de deep learning. Aceste explicatii va pot ajuta sa obtineti o idee mai intuitiva a ceea ce trebuie sa cautati intr-un GPU. Vom discuta despre caracteristicile unice ale noii serie de GPU NVIDIA RTX 40 Ampere care merita luate in considerare daca cumparati un GPU. De acolo, fac recomandari GPU pentru diferite scenarii. Dupa aceea urmeaza o sectiune de intrebari si raspunsuri cu intrebari frecvente care mi-au fost adresate in firele de pe Twitter; in acea sectiune, voi aborda si conceptiile gresite comune si unele probleme diverse, cum ar fi cloud vs desktop, racire, AMD vs NVIDIA si altele.
Cum functioneaza GPU-urile?
Daca utilizati frecvent GPU-uri, este util sa intelegeti cum functioneaza acestea. Aceste cunostinte va vor ajuta sa intelegeti cazurile in care GPU-urile sunt rapide sau lente. La randul sau, s-ar putea sa intelegeti mai bine de ce aveti nevoie de un GPU in primul rand si cum alte optiuni hardware viitoare ar putea concura. Puteti sari peste aceasta sectiune daca doriti doar cifrele utile si argumentele de performanta care sa va ajute sa decideti ce GPU sa cumparati. Cea mai buna explicatie la nivel inalt pentru intrebarea cum functioneaza GPU-urile este urmatorul raspuns Quora:
Cititi raspunsul lui Tim Dettmers la De ce sunt GPU-urile potrivite pentru invatarea profunda? pe Quora
Aceasta este o explicatie de nivel inalt care explica destul de bine de ce GPU-urile sunt mai bune decat procesoarele pentru invatare profunda. Daca ne uitam la detalii, putem intelege ce face un GPU mai bun decat altul.
Cele mai importante specificatii GPU pentru viteza de procesare a invatarii profunde
Aceasta sectiune va poate ajuta sa construiti o intelegere mai intuitiva a modului in care sa va ganditi la performanta invatarii profunde. Aceasta intelegere va va ajuta sa evaluati singur GPU-urile viitoare. Aceasta sectiune este sortata dupa importanta fiecarei componente. Tensor Cores sunt cele mai importante, urmate de latimea de banda a memoriei unui GPU, ierahia cache-ului si numai apoi FLOPS-urile unui GPU.
Miezuri tensoare
Miezurile tensoare sunt nuclee minuscule care efectueaza o multiplicare foarte eficienta a matricei. Deoarece cea mai scumpa parte a oricarei retele neuronale profunde este multiplicarea matricei, nucleele tensoare sunt foarte utile. In rapid, sunt atat de puternice, incat nu recomand niciun GPU care sa nu aiba Tensor Cores.
Este util sa intelegem cum functioneaza pentru a aprecia importanta acestor unitati de calcul specializate pentru multiplicarea matricelor. Aici va voi arata un exemplu simplu de multiplicare a matricei A*B=C, in care toate matricele au o dimensiune de 32×32, cum arata un model de calcul cu si fara nuclee tensor. Acesta este un exemplu simplificat si nu modul exact in care ar fi scris un nucleu de multiplicare a matricei performant, dar are toate elementele de baza. Un programator CUDA ar lua acest lucru ca pe o prima „schita” si apoi ar optimiza-o pas cu pas cu concepte precum tamponarea dubla, optimizarea registrului, optimizarea ocuparii, paralelismul la nivel de instructie si multe altele, despre care nu le voi discuta in acest moment .
Pentru a intelege pe deplin acest exemplu, trebuie sa intelegeti conceptele de cicluri. Daca un procesor ruleaza la 1GHz, poate face 10^9 cicluri pe secunda. Fiecare ciclu reprezinta o oportunitate de calcul. Cu toate acestea, de cele mai multe ori, operatiunile dureaza mai mult de un ciclu. Astfel, avem in esenta o coada in care operatiunile urmatoare trebuie sa astepte ca urmatoarea operatie sa se termine. Aceasta se mai numeste si latenta operatiei.
Iata cateva momente importante ale ciclului de latenta pentru operatiuni. Aceste timpi se pot schimba de la generarea GPU la generarea GPU. Aceste numere sunt pentru GPU-urile Ampere, care au cache relativ lente.
- Acces global la memorie (pana la 80 GB): ~ 380 de cicluri
- Cache L2: ~200 de cicluri
- Cache L1 sau acces la memorie partajata (pana la 128 kb per multiprocesor de streaming): ~34 de cicluri
- Inmultire si adunare fuzionate, a*b+c (FFMA): 4 cicluri
- Inmultirea matricei Tensor Core: 1 ciclu
Fiecare operatie este intotdeauna efectuata de un pachet de 32 de fire. Acest pachet este numit urzeala de fire. Urzelile functioneaza de obicei intr-un model sincron – firele dintr-o urzeala trebuie sa se astepte unul pe celalalt. Toate operatiunile de memorie de pe GPU sunt optimizate pentru warps. De exemplu, incarcarea din memoria globala are loc la o granularitate de 32*4 octeti, exact 32 float, exact un float pentru fiecare fir dintr-un warp. Putem avea pana la 32 warps = 1024 fire intr-un multiprocesor de streaming (SM), echivalentul GPU al unui nucleu CPU. Resursele unui SM sunt impartite intre toate warpurile active. Aceasta inseamna ca uneori dorim sa rulam mai putine warp pentru a avea mai multe registre/memorie partajata/resurse Tensor Core per warp.
Pentru ambele exemple de mai jos, presupunem ca avem aceleasi resurse de calcul. Pentru acest mic exemplu de multiplicare a matricei 32×32, folosim 8 SM-uri (aproximativ 10% dintr-un RTX 3090) si 8 warps per SM.
Pentru a intelege modul in care latentele ciclului joaca impreuna cu resurse precum firele de executie per SM si memoria partajata pe SM, acum ne uitam la exemple de multiplicare a matricei. In timp ce urmatorul exemplu urmeaza in general secventa pasilor de calcul ai inmultirii matricei atat cu cat si fara nuclee tensor, va rugam sa retineti ca acestea sunt exemple foarte simplificate. Cazurile reale de multiplicare a matricei implica placi de memorie partajata mult mai mari si modele de calcul usor diferite.
Inmultirea matricei fara nuclee tensoare
Daca vrem sa facem o inmultire a matricei A*B=C, unde fiecare matrice are dimensiunea 32×32, atunci vrem sa incarcam memoria pe care o accesam in mod repetat in memoria partajata, deoarece latenta sa este de aproximativ cinci ori mai mica (200 de cicluri fata de 34 de cicluri). cicluri). Un bloc de memorie din memoria partajata este adesea denumit o placa de memorie sau doar o placa. Incarcarea a doua flotoare de 32×32 intr-o placa de memorie partajata se poate intampla in paralel, folosind 2*32 warps. Avem 8 SM-uri cu 8 warps fiecare, asa ca, datorita paralelizarii, trebuie sa facem doar o singura incarcare secventiala de la memoria globala la cea partajata, care dureaza 200 de cicluri.
Pentru a face multiplicarea matricei, acum trebuie sa incarcam un vector de 32 de numere din memoria partajata A si din memoria partajata B si sa efectuam o inmultire si acumulare fuzionata (FFMA). Apoi stocati iesirile in registrele C. Impartim munca astfel incat fiecare SM sa faca produse punctiforme de 8x (32×32) pentru a calcula 8 iesiri ale lui C. De ce acesta este exact 8 (4 in algoritmii mai vechi) este foarte tehnic. Recomand postarea pe blog a lui Scott Gray despre multiplicarea matricei pentru a intelege acest lucru. Aceasta inseamna ca avem 8x accesari la memorie partajata la costul a 34 de cicluri fiecare si 8 operatiuni FFMA (32 in paralel), care costa 4 cicluri fiecare. In total, avem astfel un cost de:
200 cicluri (memorie globala) + 8*34 cicluri (memorie partajata) + 8*4 cicluri (FFMA) = 504 cicluri
Sa ne uitam la costul ciclului de utilizare a Tensor Cores.
Inmultirea matricei cu nuclee tensoare
Cu Tensor Cores, putem efectua o multiplicare a matricei 4×4 intr-un singur ciclu. Pentru a face asta, trebuie mai intai sa introducem memorie in Tensor Core. Similar cu cele de mai sus, trebuie sa citim din memoria globala (200 de cicluri) si sa stocam in memoria partajata. Pentru a face o inmultire a matricei 32×32, trebuie sa facem operatii 8×8=64 Tensor Cores. Un singur SM are 8 nuclee tensor. Deci, cu 8 SM-uri, avem 64 de nuclee tensor – doar numarul de care avem nevoie! Putem transfera datele din memoria partajata la Tensor Cores cu 1 transfer de memorie (34 de cicluri) si apoi sa facem acele 64 de operatii paralele Tensor Core (1 ciclu). Aceasta inseamna ca costul total pentru multiplicarea matricei Tensor Cores, in acest caz, este:
200 de cicluri (memorie globala) + 34 de cicluri (memorie partajata) + 1 ciclu (Tensor Core) = 235 de cicluri.
Astfel, reducem semnificativ costul de multiplicare a matricei de la 504 cicluri la 235 cicluri prin Tensor Cores. In acest caz simplificat, Tensor Cores a redus atat costul accesului la memorie partajata, cat si al operatiunilor FFMA.
Acest exemplu este simplificat, de exemplu, de obicei, fiecare fir trebuie sa calculeze in ce memorie sa citeasca si sa scrie pe masura ce transferati date din memoria globala in memoria partajata. Cu noile arhitecturi Hooper (H100), avem, in plus, Tensor Memory Accelerator (TMA) sa calculeze acesti indici in hardware si astfel ajuta fiecare fir sa se concentreze pe mai mult calcul, mai degraba decat pe indici de calcul.
Inmultirea matricei cu nuclee tensor si copii asincrone (RTX 30/RTX 40) si TMA (H100)
GPU-urile din seria RTX 30 Ampere si RTX 40 Ada au suport suplimentar pentru a efectua transferuri asincrone intre memoria globala si cea partajata. GPU-ul H100 Hopper extinde acest lucru si mai mult prin introducerea unitatii Tensor Memory Accelerator (TMA). unitatea TMA combina copiile asincrone si calculul indexului pentru citire si scriere simultan – astfel incat fiecare fir nu mai trebuie sa calculeze care este urmatorul element de citit si fiecare fir se poate concentra pe efectuarea mai multor calcule de multiplicare a matricei. Aceasta arata dupa cum urmeaza.
Unitatea TMA preia memoria din memoria globala in memoria partajata (200 de cicluri). Odata ce datele sosesc, unitatea TMA preia urmatorul bloc de date in mod asincron din memoria globala. In timp ce acest lucru se intampla, firele de executie incarca date din memoria partajata si efectueaza multiplicarea matricei prin miezul tensorului. Odata ce firele sunt terminate, acestea asteapta ca unitatea TMA sa termine urmatorul transfer de date, iar secventa se repeta.
Ca atare, din cauza naturii asincrone, a doua memorie globala citita de unitatea TMA progreseaza deja, pe masura ce firele de executie proceseaza tile de memorie partajata curenta. Aceasta inseamna ca a doua citire dureaza doar 200 – 34 – 1 = 165 de cicluri.
Deoarece facem multe citiri, doar primul acces la memorie va fi lent si toate celelalte accesari la memorie vor fi partial suprapuse cu unitatea TMA. Astfel, in medie, reducem timpul cu 35 de cicluri.
165 de cicluri (asteptati finalizarea copiei asincrone) + 34 de cicluri (memorie partajata) + 1 ciclu (Tensor Core) = 200 de cicluri.
Ceea ce accelereaza inmultirea matricei cu inca 15%.
Din aceste exemple, devine clar de ce urmatorul atribut, latimea de banda a memoriei, este atat de crucial pentru GPU-urile echipate cu Tensor-Core. Deoarece memoria globala este de departe cel mai mare cost de ciclu pentru multiplicarea matricei cu Tensor Cores, am avea chiar si GPU-uri mai rapide daca latenta memoriei globale ar putea fi redusa. Putem face acest lucru fie prin cresterea frecventei de ceas a memoriei (mai multe cicluri pe secunda, dar si mai multe cerinte de caldura si energie mai mare), fie prin cresterea numarului de elemente care pot fi transferate la un moment dat (latimea magistralei).
-
LLM.int8() si caracteristici emergente
-

Cum sa-ti alegi scoala de licenta
Latimea de banda a memoriei
Din sectiunea anterioara, am vazut ca Tensor Cores sunt foarte rapide. Atat de repede, de fapt, incat sunt inactivi de cele mai multe ori, in timp ce asteapta ca memoria sa soseasca din memoria globala. De exemplu, in timpul antrenamentului de dimensiune GPT-3, care utilizeaza matrici uriase – cu cat mai mari, cu atat mai bine pentru Tensor Cores – avem o utilizare TFLOPS Tensor Core de aproximativ 45-65%, ceea ce inseamna ca chiar si pentru retelele neuronale mari aproximativ 50% din timp, Tensor Cores sunt inactiv.
Aceasta inseamna ca atunci cand comparam doua GPU-uri cu Tensor Cores, unul dintre cei mai buni indicatori pentru performanta fiecarui GPU este latimea de banda a memoriei. De exemplu, GPU-ul A100 are o latime de banda de memorie de 1.555 GB/s fata de 900 GB/s a V100. Ca atare, o estimare de baza a acceleratiei unui A100 fata de V100 este 1555/900 = 1,73x.
Cache L2 / Memorie partajata / Cache L1 / Registre
Deoarece transferurile de memorie catre nucleele Tensor sunt factorul limitator al performantei, cautam alte atribute GPU care sa permita un transfer mai rapid de memorie catre nucleele Tensor. Cache-ul L2, memoria partajata, cache-ul L1 si cantitatea de registre utilizate sunt toate legate. Pentru a intelege modul in care o ierarhie de memorie permite transferuri mai rapide de memorie, ajuta la intelegerea modului in care se realizeaza multiplicarea matricei pe un GPU.
Pentru a efectua multiplicarea matricei, exploatam ierarhia de memorie a unui GPU care trece de la memorie globala lenta, la memorie L2 mai rapida, la memorie partajata locala rapida, la registre fulgeratoare. Cu toate acestea, cu cat memoria este mai rapida, cu atat este mai mica.
Desi in mod logic, memoria L2 si L1 sunt aceleasi, memoria cache L2 este mai mare si, prin urmare, distanta fizica medie care trebuie parcursa pentru a prelua o linie de cache este mai mare. Puteti vedea cache-urile L1 si L2 ca depozite organizate in care doriti sa recuperati un articol. Stiti unde este articolul, dar pentru a ajunge acolo dureaza in medie mult mai mult pentru depozitul mai mare. Aceasta este diferenta esentiala dintre cache-urile L1 si L2. Mare = lent, mic = rapid.
Pentru multiplicarea matricei putem folosi aceasta separare ierarhica in bucati de memorie din ce in ce mai mici si, prin urmare, din ce in ce mai rapide de memorie pentru a efectua inmultiri de matrice foarte rapide. Pentru aceasta, trebuie sa impartim inmultirea matricei mari in inmultiri sub-matrice mai mici. Aceste bucati sunt numite placi de memorie sau adesea pentru scurte placi.
Efectuam multiplicarea matricei pe aceste placi mai mici in memoria partajata locala, care este rapida si aproape de multiprocesorul de streaming (SM) – echivalentul unui nucleu CPU. Cu Tensor Cores, facem un pas mai departe: luam fiecare tigla si incarcam o parte din aceste tigle in Tensor Cores, care este adresata direct de registre. O placa de memorie matrice din memoria cache L2 este de 3-5 ori mai rapida decat memoria GPU globala (RAM GPU), memoria partajata este de ~7-10 ori mai rapida decat memoria GPU globala, in timp ce registrele Tensor Cores sunt de ~200 ori mai rapide decat memoria GPU globala .
Avand placi mai mari inseamna ca putem reutiliza mai multa memorie. Am scris despre asta in detaliu in postarea mea de blog TPU vs GPU. De fapt, puteti vedea TPU-urile ca avand placi foarte, foarte, mari pentru fiecare Tensor Core. Ca atare, TPU-urile pot reutiliza mult mai multa memorie cu fiecare transfer din memoria globala, ceea ce le face putin mai eficiente la multiplicarea matricei decat GPU-urile.
Dimensiunea fiecarei placi este determinata de cata memorie avem pe multiprocesor de streaming (SM) si de cata memorie cache L2 avem pe toate SM-urile. Avem urmatoarele dimensiuni de memorie partajata pe urmatoarele arhitecturi:
- Volta (Titan V): 128 kb memorie partajata / 6 MB L2
- Turing (seria RTX 20s): 96 kb memorie partajata / 5,5 MB L2
- Amperi (seria RTX 30s): 128 kb memorie partajata / 6 MB L2
- Ada (seria RTX 40s): 128 kb memorie partajata / 72 MB L2
Vedem ca Ada are un cache L2 mult mai mare, permitand dimensiuni mai mari, ceea ce reduce accesul global la memorie. De exemplu, pentru BERT mare in timpul antrenamentului, intrarea si matricea de greutate a oricarei inmultiri de matrice se potrivesc perfect in memoria cache L2 a lui Ada (dar nu si altor noi). Ca atare, datele trebuie sa fie incarcate din memoria globala o singura data, iar apoi datele sunt disponibile prin cache-ul L2, facand multiplicarea matricei de aproximativ 1,5 – 2,0 ori mai rapida pentru aceasta arhitectura pentru Ada. Pentru modelele mai mari, acceleratiile sunt mai mici in timpul antrenamentului, dar exista anumite puncte de lucru care pot face anumite modele mult mai rapide. Deducerea, cu o dimensiune a lotului mai mare de 8, poate beneficia, de asemenea, enorm de pe urma cache-urilor L2 mai mari.
Estimarea performantei de invatare profunda Ada / Hopper
Aceasta sectiune este pentru cei care doresc sa inteleaga mai multe detalii tehnice despre modul in care obtin estimarile de performanta pentru GPU-urile Ampere. Daca nu va pasa de aceste aspecte tehnice, puteti sari peste aceasta sectiune.
Estimari practice de viteza Ada / Hopper
Sa presupunem ca avem o estimare pentru un GPU al unei arhitecturi GPU precum Hopper, Ada, Ampere, Turing sau Volta. Este usor sa extrapolati aceste rezultate la alte GPU-uri din aceeasi arhitectura/serie. Din fericire, NVIDIA a evaluat deja A100 vs V100 vs H100 intr-o gama larga de sarcini de viziune pe computer si intelegere a limbajului natural. Din pacate, NVIDIA s-a asigurat ca aceste numere nu sunt direct comparabile prin utilizarea diferitelor dimensiuni de lot si a numarului de GPU-uri ori de cate ori este posibil pentru a favoriza rezultatele pentru GPU-ul H100. Deci, intr-un fel, cifrele de referinta sunt partial sincere, partial numere de marketing. In general, ati putea argumenta ca utilizarea unor loturi mai mari este corecta, deoarece GPU-ul H100/A100 are mai multa memorie. Totusi, pentru a compara arhitecturile GPU, ar trebui sa evaluam performanta impartiala a memoriei cu aceeasi dimensiune a lotului.
Pentru a obtine o estimare impartiala, putem scala rezultatele GPU ale centrului de date in doua moduri: (1) luam in considerare diferentele de dimensiune a lotului, (2) luam in considerare diferentele in utilizarea GPU-urilor 1 fata de 8. Suntem norocosi ca putem gasi o astfel de estimare pentru ambele partiniri in datele pe care NVIDIA le furnizeaza.
Dublarea dimensiunii lotului creste debitul in termeni de imagini/e (CNN) cu 13,6%. Am evaluat aceeasi problema pentru transformatoarele de pe RTX Titan si am gasit, in mod surprinzator, acelasi rezultat: 13,5% – se pare ca aceasta este o estimare solida.
Pe masura ce paralelizam retelele pe tot mai multe GPU-uri, pierdem performanta din cauza unei suprasarcini de retea. Sistemul GPU A100 8x are o retea mai buna (NVLink 3.0) decat sistemul GPU V100 8x (NVLink 2.0) – acesta este un alt factor de confuzie. Privind direct la datele de la NVIDIA, putem constata ca pentru CNN-uri, un sistem cu 8x A100 are o suprasarcina cu 5% mai mica decat un sistem de 8x V100. Aceasta inseamna ca daca trecerea de la 1x A100 la 8x A100 va ofera o accelerare de, sa zicem, 7,00x, atunci trecerea de la 1x V100 la 8x V100 va ofera doar o accelerare de 6,67x. Pentru transformatoare, cifra este de 7%.
Folosind aceste cifre, putem estima accelerarea pentru cateva arhitecturi specifice de deep learning din datele directe pe care NVIDIA le furnizeaza. Tesla A100 ofera urmatoarea accelerare fata de Tesla V100:
- SE-ResNeXt101: 1,43x
- Mask-R-CNN: 1,47x
- Transformator (12 straturi, traducere automata, WMT14 en-de): 1,70x
Astfel, cifrele sunt putin mai mici decat estimarea teoretica pentru viziunea computerizata. Acest lucru s-ar putea datora dimensiunilor tensorilor mai mici, supraincarcarii de la operatiuni care sunt necesare pentru a pregati multiplicarea matricei, cum ar fi img2col sau Fast Fourier Transform (FFT) sau operatiuni care nu pot satura GPU (straturile finale sunt adesea relativ mici). Ar putea fi, de asemenea, artefacte ale arhitecturilor specifice (convolutie grupata).
Estimarea practica a transformatorului este foarte apropiata de estimarea teoretica. Acest lucru se datoreaza probabil ca algoritmii pentru matrici uriase sunt foarte simpli. Voi folosi aceste estimari practice pentru a calcula rentabilitatea GPU-urilor.
Posibile partiniri in estimari
Estimarile de mai sus sunt pentru GPU-uri H100, A100 si V100. In trecut, NVIDIA a introdus pe furis degradari neanuntate de performanta in GPU-urile RTX „de gaming”: (1) Scaderea utilizarii Tensor Core, (2) ventilatoare de jocuri pentru racire, (3) transferuri GPU peer-to-peer dezactivate. Este posibil sa existe degradari neanuntate de performanta in seria RTX 40 in comparatie cu Hopper H100 complet.
De acum, una dintre aceste degradari a fost gasita pentru GPU-urile Ampere: performanta Tensor Core a fost scazuta, astfel incat GPU-urile din seria RTX 30 sa nu fie la fel de bune ca placile Quadro in scopuri de deep learning. Acest lucru a fost facut si pentru seria RTX 20, deci nu este nimic nou, dar de data aceasta s-a facut si pentru cardul echivalent Titan, RTX 3090. RTX Titan nu avea activata degradarea performantei.
In prezent, nu se cunoaste nicio degradare pentru GPU-urile Ada, dar actualizez aceasta postare cu stiri despre asta si ii anunt pe adeptii mei de pe twitter.
Avantaje si probleme pentru seriile RTX40 si RTX 30
Noua serie NVIDIA Ampere RTX 30 are beneficii suplimentare fata de seria NVIDIA Turing RTX 20, cum ar fi antrenamentul de retea limitat si inferenta. Alte caracteristici, cum ar fi noile tipuri de date, ar trebui privite mai mult ca o caracteristica usoara in utilizare, deoarece ofera aceeasi crestere a performantei ca si Turing, dar fara a fi necesara nicio programare suplimentara.
Seria Ada RTX 40 are si mai multe progrese, cum ar fi nucleele tensoare Float pe 8 biti (FP8). Seria RTX 40 are, de asemenea, probleme similare de putere si temperatura in comparatie cu RTX 30. Problema topirii cablurilor de conectare de alimentare in RTX 40 poate fi prevenita cu usurinta prin conectarea corecta a cablului de alimentare.
Instruire in retea rara
Amperii permite multiplicarea automata a matricei rare cu structura fina la viteze dense. Cum functioneaza asta? Luati o matrice de greutate si taiati-o in bucati de 4 elemente. Acum imaginati-va ca 2 elemente din aceste 4 sunt zero. Figura 1 arata cum ar putea arata.
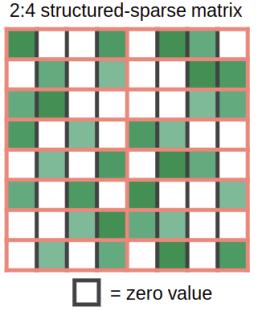
Figura 1: Structura sustinuta de caracteristica de multiplicare a matricei rare in GPU-urile Ampere. Cifra este preluata din prezentarea lui Jeff Pool GTC 2020 despre Accelerating Sparsity in the NVIDIA Ampere Architecture, prin amabilitatea NVIDIA.
Cand multiplicati aceasta matrice de greutate rara cu unele intrari dense, caracteristica miezului tensorului matricei rare din Ampere comprima automat matricea rara la o reprezentare densa care este jumatate din dimensiunea asa cum se poate vedea in Figura 2. Dupa aceasta compresie, matricea dens comprimata tigla este introdusa in miezul tensor care calculeaza o multiplicare a matricei de doua ori dimensiunea obisnuita. Acest lucru duce efectiv la o accelerare de 2 ori, deoarece cerintele de latime de banda in timpul inmultirii matricei din memoria partajata sunt reduse la jumatate.
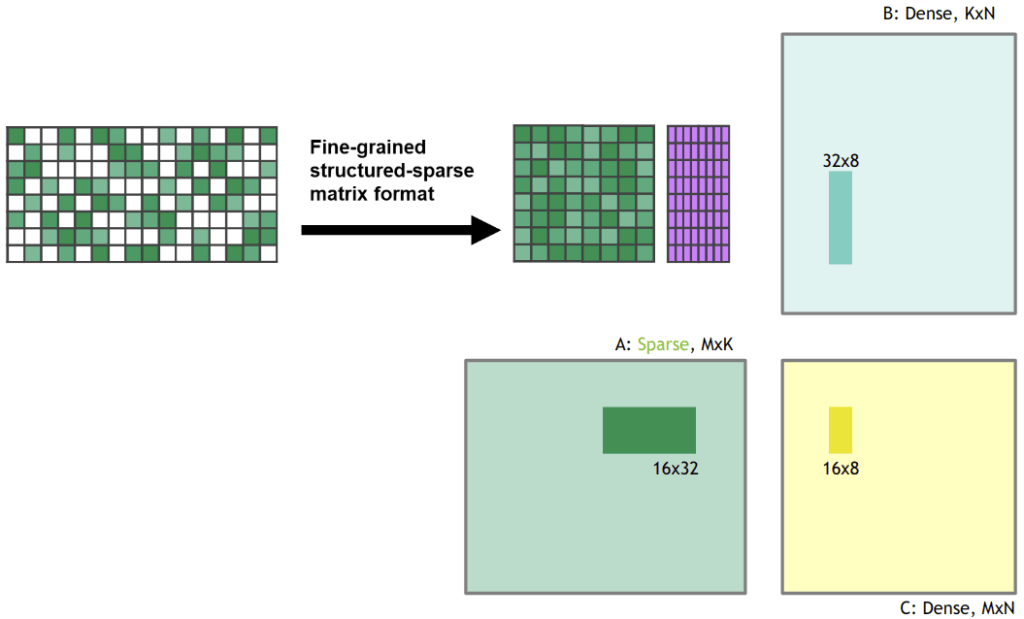
Figura 2: Matricea rara este comprimata la o reprezentare densa inainte de efectuarea inmultirii matricei. Cifra este preluata din prezentarea lui Jeff Pool GTC 2020 despre Accelerating Sparsity in the NVIDIA Ampere Architecture, prin amabilitatea NVIDIA.
Lucram la formarea in retea rara in cercetarea mea si am scris, de asemenea, o postare pe blog despre formarea rara. O critica la adresa muncii mele a fost ca „Reduceti FLOPS-ul necesar pentru retea, dar nu genereaza acceleratii, deoarece GPU-urile nu pot face multiplicarea rapida a matricei rare”. Ei bine, cu adaugarea caracteristicii de multiplicare a matricei rare pentru Tensor Cores, algoritmul meu sau alti algoritmi de antrenament rare, acum ofera de fapt acceleratii de pana la 2x in timpul antrenamentului.
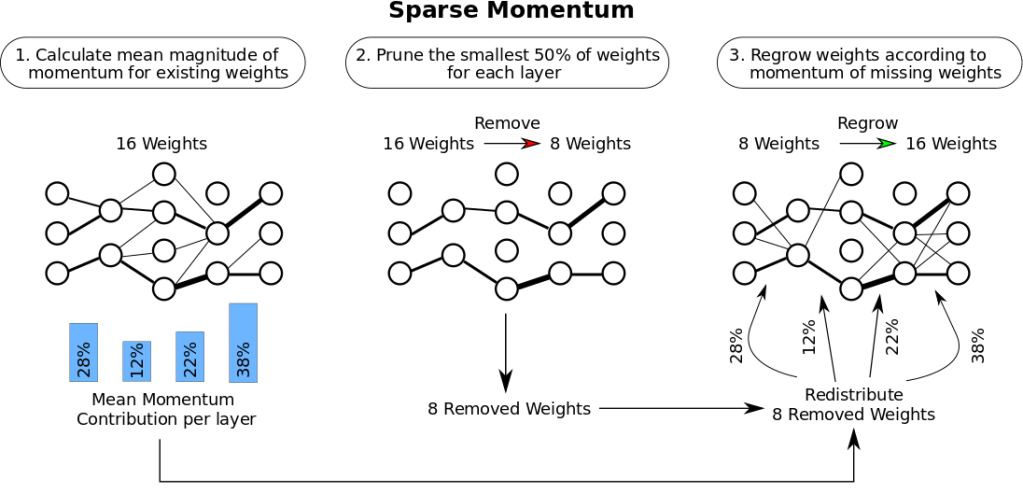
Figura 3: Algoritmul de antrenament rar pe care l-am dezvoltat are trei etape: (1) Determinati importanta fiecarui strat. (2) Indepartati cele mai mici greutati neimportante. (3) Cresteti noi greutati proportionale cu importanta fiecarui strat. Cititi mai multe despre munca mea in postarea mea pe blogul de formare.
Desi aceasta caracteristica este inca experimentala si antrenarea retelelor rare nu este inca obisnuita, avand aceasta caracteristica pe GPU inseamna ca sunteti pregatit pentru viitorul antrenamentului limitat.
Calcul cu precizie scazuta
In munca mea, am aratat anterior ca noile tipuri de date pot imbunatati stabilitatea in timpul retropropagarii cu precizie redusa.
![Figura 4: Tipuri de date pe 8 biti de deep learning de precizie scazuta pe care le-am dezvoltat. Formarea de deep learning beneficiaza de tipuri de date foarte specializate. Tipul meu de date arbore dinamic foloseste un bit dinamic care indica inceputul unui arbore de bisectare binar care a cuantificat intervalul [0, 0,9], in timp ce toti bitii anteriori sunt folositi pentru exponent. Acest lucru permite reprezentarea dinamica a numerelor care sunt atat mari, cat si mici, cu mare precizie.](https://tribunaeconomica.ro/wp-content/uploads/2023/09/4_ce-gpu-e-aveti-nevoie-pentru-deep-learning.png)
Figura 4: Tipuri de date pe 8 biti de deep learning de precizie scazuta pe care le-am dezvoltat. Formarea de deep learning beneficiaza de tipuri de date foarte specializate. Tipul meu de date arbore dinamic foloseste un bit dinamic care indica inceputul unui arbore de bisectare binar care a cuantificat intervalul [0, 0,9], in timp ce toti bitii anteriori sunt folositi pentru exponent. Acest lucru permite reprezentarea dinamica a numerelor care sunt atat mari, cat si mici, cu mare precizie.
In prezent, daca doriti sa aveti o propagare inversa stabila cu numere in virgula mobila pe 16 biti (FP16), marea problema este ca tipurile obisnuite de date FP16 accepta doar numere in intervalul [-65.504, 65.504]. Daca gradientul dvs. aluneca peste acest interval, gradientii dvs. explodeaza in valori NaN. Pentru a preveni acest lucru in timpul antrenamentului FP16, de obicei efectuam o scalare a pierderilor in care inmultiti pierderea cu un numar mic inainte de propagarea inversa pentru a preveni aceasta explozie de gradient.
Formatul BrainFloat 16 (BF16) foloseste mai multi biti pentru exponent, astfel incat intervalul de numere posibile este acelasi ca pentru FP32: [-3*10^38, 3*10^38]. BF16 are o precizie mai mica, adica cifre semnificative, dar precizia gradientului nu este atat de importanta pentru invatare. Deci, ceea ce face BF16 este ca nu mai trebuie sa faceti nicio reducere a pierderilor sau sa va faceti griji ca gradientul va exploda rapid. Ca atare, ar trebui sa vedem o crestere a stabilitatii antrenamentului prin utilizarea formatului BF16 ca o usoara pierdere de precizie.
Ce inseamna asta pentru tine: Cu precizia BF16, antrenamentul ar putea fi mai stabil decat cu precizia FP16, oferind in acelasi timp aceleasi acceleratii. Cu precizie TensorFloat (TF32) de 32 de biti, ajungeti aproape de stabilitatea FP32, oferind in acelasi timp viteze apropiate de FP16. Lucrul bun este ca, pentru a utiliza aceste tipuri de date, puteti inlocui pur si simplu FP32 cu TF32 si FP16 cu BF16 – nu sunt necesare modificari de cod!
In general, totusi, aceste noi tipuri de date pot fi vazute ca tipuri de date lenese, in sensul ca ati fi putut obtine toate beneficiile cu vechile tipuri de date cu unele eforturi suplimentare de programare (scalarea corecta a pierderilor, initializarea, normalizarea, folosind Apex). Ca atare, aceste tipuri de date nu ofera accelerari, ci mai degraba imbunatatesc usurinta de utilizare a preciziei scazute pentru antrenament.
-
LLM.int8() si caracteristici emergente
-
Cum sa-ti alegi scoala de licenta
Designul ventilatoarelor si problemele de temperatura ale GPU-urilor
In timp ce noul design de ventilator al seriei RTX 30 functioneaza foarte bine la racirea GPU-ului, diferite modele de ventilatoare ale GPU-urilor editiei non-fondatoare ar putea fi mai problematice. Daca GPU-ul tau se incalzeste peste 80C, se va accelera si isi va incetini viteza/puterea de calcul. Aceasta supraincalzire se poate intampla in special daca stivuiti mai multe GPU-uri unul langa celalalt. O solutie la aceasta este utilizarea extensiilor PCIe pentru a crea spatiu intre GPU-uri.
Raspandirea GPU-urilor cu extensii PCIe este foarte eficienta pentru racire si pentru alti colegi doctoranzi de la Universitatea din Washington si folosesc aceasta configuratie cu mare succes. Nu arata frumos, dar va pastreaza GPU-urile la rece! Acesta functioneaza fara probleme de 4 ani acum. De asemenea, poate ajuta daca nu aveti suficient spatiu pentru a incapea toate GPU-urile in sloturile PCIe. De exemplu, daca puteti gasi spatiu intr-o carcasa de computer desktop, ar putea fi posibil sa cumparati un RTX 4090 standard cu 3 sloturi si sa le distribuiti cu extensii PCIe in carcasa. Cu aceasta, puteti rezolva atat problema spatiului, cat si problema racirii pentru o configurare 4x RTX 4090 cu o singura solutie simpla.

Figura 5: 4x GPU-uri cu extensii PCIe. Pare o mizerie, dar este foarte eficient pentru racire. Am folosit aceasta platforma timp de 4 ani si racirea este excelenta, in ciuda GPU-urilor problematice RTX 2080 Ti Founders Edition.
Probleme de proiectare si alimentare cu 3 sloturi
RTX 3090 si RTX 4090 sunt GPU-uri cu 3 sloturi, asa ca nu le va putea folosi intr-o configurare de 4x cu designul implicit al ventilatorului de la NVIDIA. Acest lucru este oarecum justificat deoarece ruleaza la peste 350 W TDP si va fi dificil sa se raceasca intr-o setare multi-GPU cu 2 sloturi. RTX 3080 este doar putin mai bun la 320W TDP, iar racirea unei configuratii 4x RTX 3080 va fi, de asemenea, foarte dificila.
De asemenea, este dificil sa alimentati un sistem 4x 350W = 1400W sau 4x 450W = 1800W in carcasa 4x RTX 3090 sau 4x RTX 4090. Unitatile de alimentare (PSU) de 1600 W sunt usor disponibile, dar avand doar 200 W pentru a alimenta procesorul si placa de baza poate fi prea strans. Puterea maxima a componentelor este utilizata numai daca componentele sunt utilizate pe deplin, iar in procesul de invatare profunda, CPU este de obicei doar sub sarcina slaba. Cu asta, un PSU de 1600 W ar putea functiona destul de bine cu o versiune RTX 3080 de 4x, dar pentru o versiune RTX 3090 de 4x, este mai bine sa cautati surse de alimentare cu putere mare (+1700W). Unii dintre adeptii mei au avut un mare succes cu PSU-urile criptominarii – aruncati o privire in sectiunea de comentarii pentru mai multe informatii despre asta. In caz contrar, este important de retinut ca nu toate prizele accepta surse de alimentare de peste 1600 W, in special in SUA. Acesta este motivul pentru care in SUA, In prezent, pe piata exista putine surse de alimentare standard pentru desktop peste 1600 W. Daca obtineti un server sau unitati de alimentare pentru criptominere, aveti grija la factorul de forma – asigurati-va ca se potriveste in carcasa computerului dvs.
Limitarea puterii: o solutie eleganta pentru a rezolva problema cu puterea?
Este posibil sa setati o limita de putere pe GPU-urile dvs. Asa ca ati putea sa setati programatic limita de putere a unui RTX 3090 la 300W in loc de 350W standard. Intr-un sistem GPU 4x, aceasta este o economie de 200 W, care ar putea fi suficienta pentru a construi un sistem RTX 3090 de 4x cu un PSU de 1600 W fezabil. De asemenea, ajuta la mentinerea GPU-urilor la rece. Asadar, setarea unei limite de putere poate rezolva cele doua probleme majore ale setarilor unui RTX 3080 4x sau RTX 3090 4x, racire si putere, in acelasi timp. Pentru o configurare de 4x, mai aveti nevoie de GPU-uri eficiente (si designul standard se poate dovedi adecvat pentru aceasta), dar acest lucru rezolva problema PSU.

Figura 6: Reducerea limitei de putere are un efect usor de racire. Reducerea limitei de putere a RTX 2080 Ti cu 50-60 W scade usor temperaturile, iar ventilatoarele functioneaza mai silentioase.
S-ar putea sa intrebati: „Acest lucru nu incetineste GPU-ul?” Da, da, dar intrebarea este cat de mult. Am evaluat sistemul 4x RTX 2080 Ti prezentat in Figura 5 sub diferite limite de putere pentru a testa acest lucru. Am evaluat timpul pentru 500 de mini-loturi pentru BERT Large in timpul inferentei (excluzand stratul softmax). Aleg BERT Large inference deoarece, din experienta mea, acesta este modelul de deep learning care streseaza cel mai mult GPU-ul. Ca atare, m-as astepta ca limitarea puterii sa aiba cea mai mare incetinire pentru acest model. Ca atare, incetinirile raportate aici sunt probabil aproape de incetinirile maxime la care va puteti astepta. Rezultatele sunt prezentate in Figura 7.

Figura 7: Incetinire masurata pentru o limita de putere data pe un RTX 2080 Ti. Masuratorile efectuate sunt timpii medii de procesare pentru 500 de mini-loturi de BERT Large in timpul inferentei (excluzand stratul softmax).
Dupa cum putem vedea, setarea limitei de putere nu afecteaza in mod serios performanta. Limitarea puterii cu 50 W – mai mult decat suficient pentru a gestiona 4x RTX 3090 – scade performanta cu doar 7%.
RTX 4090s si conectori de putere topire: Cum sa preveniti problemele
A existat o conceptie gresita ca cablurile de alimentare RTX 4090 se topesc pentru ca erau indoite. Cu toate acestea, s-a constatat ca doar 0,1% dintre utilizatori au avut aceasta problema si problema a aparut din cauza unei erori de utilizator. Iata un videoclip care arata ca principala problema este ca cablurile nu au fost introduse corect.
Deci, folosirea cardurilor RTX 4090 este perfect sigura daca urmati urmatoarele instructiuni de instalare:
- Daca utilizati un cablu vechi sau un GPU vechi, asigurati-va ca contactele sunt fara reziduuri/praf.
- Folositi conectorul de alimentare si introduceti-l in priza pana cand auziti un *clic* – aceasta este cea mai importanta parte.
- Testati o potrivire buna miscand cablul de alimentare de la stanga la dreapta. Cablul nu trebuie sa se miste.
- Verificati vizual contactul cu priza, nu ar trebui sa existe niciun spatiu intre cablu si priza.
Suport flotant pe 8 biti in GPU-urile din seria H100 si RTX 40
Suportul Float pe 8 biti (FP8) este un avantaj imens pentru seria RTX 40 si GPU-urile H100. Cu intrari de 8 biti, va permite sa incarcati datele pentru multiplicarea matricei de doua ori mai repede, puteti stoca de doua ori mai multe elemente de matrice in cache-urile dvs., care in arhitectura Ada si Hopper sunt foarte mari, iar acum cu nucleele tensorului FP8 obtineti 0,66 PFLOPS de calcul pentru un RTX 4090 — acesta este mai mult FLOPS decat totalitatea celui mai rapid supercomputer din lume in anul 2007. 4x RTX 4090 cu calcul FP8 rivalizeaza cu supercomputerul mai rapid din lume in anul 2010 (invatarea profunda a inceput sa functioneze chiar in 2009) .
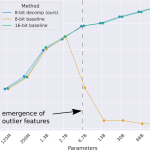
Principala problema cu utilizarea preciziei de 8 biti este ca transformatoarele pot deveni foarte instabile cu atat de putini biti si se pot prabusi in timpul antrenamentului sau pot genera nonsens in timpul inferentei. Am scris o lucrare despre aparitia instabilitatilor in modelele mari de limbaj si am scris si o postare pe blog mai accesibila.
Principalul punct de vedere este urmatorul: utilizarea pe 8 biti in loc de 16 biti face lucrurile foarte instabile, dar daca pastrati cateva dimensiuni cu precizie ridicata, totul functioneaza bine.

Principalele rezultate din munca mea privind multiplicarea matricei pe 8 biti pentru modele de limbaj mari (LLM). Putem vedea ca cea mai buna linie de baza pe 8 biti nu reuseste sa ofere performante bune de zero-shot. Metoda pe care am dezvoltat-o, LLM.int8(), poate efectua multiplicarea matricei Int8 cu aceleasi rezultate ca si linia de baza pe 16 biti.
Dar Int8 era deja suportat de GPU-urile RTX 30 / A100 / Ampere, de ce este FP8 in RTX 40 un alt upgrade mare? Tipul de date FP8 este mult mai stabil decat tipul de date Int8 si este usor de utilizat in functii precum normele de nivel sau functiile neliniare, care sunt dificil de realizat cu tipurile de date Integer. Acest lucru va face foarte simplu sa il utilizati in antrenament si inferenta. Cred ca acest lucru va face formarea si inferenta FP8 relativ comune in cateva luni.
Daca doriti sa cititi mai multe despre avantajele tipurilor de date Float vs Integer, puteti citi articolul meu recent despre legile de scalare a inferentei k-bit. Mai jos puteti vedea un rezultat principal relevant pentru tipurile de date Float vs Integer din aceasta lucrare. Putem vedea ca, bit cu bit, tipul de date FP4 pastreaza mai multe informatii decat tipul de date Int4 si, astfel, imbunatateste precizia medie LLM zeroshot in 4 sarcini.

Legile de scalare a inferentei pe 4 biti pentru modelele Pythia Large Language pentru diferite tipuri de date. Vedem ca tipurile de date float bit cu bit, pe 4 biti, au o acuratete zeroshot mai buna in comparatie cu tipurile de date Int4.
Clasamentul brut al performantei GPU-urilor
Mai jos vedem un grafic al performantei brute relevante pentru toate GPU-urile. Vedem ca exista un decalaj gigantic in performanta pe 8 biti a GPU-urilor H100 si a cardurilor vechi care sunt optimizate pentru performanta pe 16 biti.

Se arata performanta relativa bruta a transformatorului GPU-urilor. De exemplu, un RTX 4090 are o performanta de aproximativ 0,33x fata de un H100 SMX pentru inferenta pe 8 biti. Cu alte cuvinte, un H100 SMX este de trei ori mai rapid pentru inferenta pe 8 biti, comparativ cu un RTX 4090.
Pentru aceste date, nu am modelat calcul pe 8 biti pentru GPU-uri mai vechi. Am facut acest lucru, deoarece Inferenta si antrenamentul pe 8 biti sunt mult mai eficiente pe GPU-urile Ada/Hopper datorita tipului de date Float pe 8 biti si Acceleratorului de memorie Tensor (TMA), care economiseste suprasarcina de calcul a indicilor de citire/scriere, ceea ce este deosebit de util. pentru multiplicarea matricei pe 8 biti. Ada/Hopper au si suport FP8, ceea ce face in special antrenamentul pe 8 biti mult mai eficient.
Nu am modelat numere pentru antrenament pe 8 biti pentru ca pentru a modela asta trebuie sa stiu latenta cache-urilor L1 si L2 pe GPU-urile Hopper/Ada, iar acestea sunt necunoscute si nu am acces la astfel de GPU-uri. Pe Hopper/Ada, performanta de antrenament pe 8 biti poate fi de 3-4 ori mai mare decat performanta antrenamentului pe 16 biti daca cache-urile sunt la fel de rapide pe cat se zvoneste.
Dar chiar si cu noile nuclee tensor FP8 exista cateva probleme suplimentare care sunt greu de luat in considerare atunci cand modelati performanta GPU-ului. De exemplu, nucleele tensorului FP8 nu accepta multiplicarea matricei transpuse, ceea ce inseamna ca retropropagarea necesita fie o transpunere separata inainte de multiplicare, fie trebuie sa pastreze doua seturi de greutati – unul transpus si unul netranspus – in memorie. Am folosit doua seturi de greutati cand am experimentat cu antrenamentul Int8 in proiectul meu LLM.int8(), iar acest lucru a redus vitezele generale destul de semnificativ. Cred ca se poate face mai bine cu algoritmii/software-ul potrivit, dar acest lucru arata ca caracteristicile lipsa, cum ar fi multiplicarea matricei transpuse pentru nucleele tensorului, pot afecta performanta.
Pentru GPU-urile vechi, performanta de inferenta Int8 este apropiata de performanta de inferenta pe 16 biti pentru modelele sub parametrii de 13B. Performanta Int8 pe vechile GPU-uri este relevanta doar daca aveti modele relativ mari cu parametri de 175B sau mai mult. Daca sunteti interesat de performanta pe 8 biti a GPU-urilor mai vechi, puteti citi Anexa D din lucrarea mea LLM.int8() in care evaluez performanta Int8.
Performanta de invatare profunda a GPU per dolar
Mai jos vedem graficul pentru performanta per dolar american pentru toate GPU-urile sortate dupa performanta de inferenta pe 8 biti. Cum sa utilizati diagrama pentru a gasi un GPU potrivit pentru dvs. este urmatorul:
- Determinati cantitatea de memorie GPU de care aveti nevoie (euristica aproximativa: cel putin 12 GB pentru generarea imaginii; cel putin 24 GB pentru lucrul cu transformatoare)
- In timp ce inferenta si antrenamentul pe 8 biti sunt experimentale, acestea vor deveni standard in decurs de 6 luni. S-ar putea sa fie nevoie sa faceti o codificare foarte dificila pentru a lucra cu 8 biti intre timp. E bine pentru tine? Daca nu, selectati pentru performanta pe 16 biti.
- Folosind metrica determinata in (2), gasiti GPU-ul cu cea mai mare performanta relativa/dolar care are cantitatea de memorie de care aveti nevoie.
Putem vedea ca RTX 4070 Ti este cel mai rentabil pentru inferenta pe 8 si 16 biti, in timp ce RTX 3080 ramane cel mai rentabil pentru antrenament pe 16 biti. Desi aceste GPU-uri sunt cele mai rentabile, nu sunt neaparat recomandate, deoarece nu au memorie suficienta pentru multe cazuri de utilizare. Cu toate acestea, ar putea fi cartile ideale pentru a incepe calatoria dvs. de invatare profunda. Unele dintre aceste GPU-uri sunt excelente pentru competitia Kaggle, unde te poti baza adesea pe modele mai mici. Deoarece pentru a te descurca bine in competitiile Kaggle, metoda de lucru este mai importanta decat dimensiunea modelelor, multe dintre aceste GPU-uri mai mici sunt excelente pentru competitiile Kaggle.
Cele mai bune GPU-uri pentru serverele academice si de pornire par a fi GPU-urile A6000 Ada (a nu fi confundate cu A6000 Turing). GPU-ul H100 SXM este, de asemenea, foarte rentabil si are memorie mare si performante foarte puternice. Daca as construi un cluster mic pentru o companie/laborator academic, as folosi 66-80% GPU-uri A6000 si 20-33% GPU-uri H100 SXM. Daca primesc o oferta buna la GPU-uri L40, le-as alege si in loc de A6000, asa ca puteti cere oricand o oferta pentru acestea.

Afisata este performanta relativa per dolar american a GPU-urilor normalizate prin costul pentru un computer desktop si pretul mediu Amazon si eBay pentru fiecare GPU. In plus, costul de detinere al energiei electrice pentru 5 ani este adaugat la un pret al energiei electrice de 0,175 USD per kWh si o rata de utilizare a GPU de 15%. Costul energiei electrice pentru un RTX 4090 este de aproximativ 100 USD pe an. Cum sa cititi si sa interpretati graficul: un computer desktop cu carduri RTX 4070 Ti detinute timp de 5 ani ofera aproximativ de doua ori mai multa performanta de inferenta pe 8 biti per dolar, comparativ cu un GPU RTX 3090.
-
LLM.int8() si caracteristici emergente
-
Cum sa-ti alegi scoala de licenta
Recomandari GPU
Am o diagrama pentru crearea unei recomandari pe care o puteti vedea mai jos (faceti clic aici pentru aplicatia interactiva de la Nan Xiao). Desi aceasta diagrama va va ajuta in 80% din cazuri, s-ar putea sa nu functioneze pentru dvs., deoarece optiunile ar putea fi prea scumpe. In acest caz, incercati sa va uitati la benchmark-urile de mai sus si sa alegeti cel mai rentabil GPU care are inca suficienta memorie GPU pentru cazul dvs. de utilizare. Puteti estima memoria GPU necesara ruland problema dvs. in vast.ai sau Lambda Cloud pentru o perioada, astfel incat sa stiti de ce aveti nevoie. Vast.ai sau Lambda Cloud ar putea functiona bine daca aveti nevoie doar de un GPU foarte sporadic (la fiecare doua zile, timp de cateva ore) si nu trebuie sa descarcati si sa procesati un set de date mare pentru a incepe. Cu toate acestea, GPU-urile cloud nu sunt de obicei o optiune buna daca utilizati GPU-ul timp de mai multe luni cu o rata de utilizare ridicata in fiecare zi (12 ore in fiecare zi). Puteti folosi exemplul din „Cand este mai bine sa utilizati cloud-ul fata de un desktop/server GPU dedicat?” sectiunea de mai jos pentru a determina daca GPU-urile cloud sunt bune pentru dvs.

Tabel de recomandare GPU pentru GPU-urile Ada/Hopper. Urmati raspunsurile la intrebarile Da/Nu pentru a gasi GPU-ul care este cel mai potrivit pentru dvs. Desi aceasta diagrama functioneaza bine in aproximativ 80% din cazuri, s-ar putea sa ajungeti cu un GPU care este prea scump. Utilizati graficele cost/performanta de mai sus pentru a face o selectie. [aplicatie interactiva]
Este mai bine sa asteptati viitoarele GPU-uri pentru un upgrade? Viitorul GPU-urilor.
Pentru a intelege daca are sens sa sariti peste aceasta generatie si sa cumparati urmatoarea generatie de GPU-uri, este logic sa vorbim putin despre cum vor arata imbunatatirile in viitor.
In trecut, era posibil sa se micsoreze dimensiunea tranzistorilor pentru a imbunatati viteza unui procesor. Acest lucru se apropie de sfarsit acum. De exemplu, in timp ce micsorarea SRAM-ului si-a crescut viteza (distanta mai mica, acces mai rapid la memorie), acesta nu mai este cazul. Imbunatatirile actuale ale SRAM nu-i mai imbunatatesc performanta si ar putea fi chiar negative. In timp ce logica, cum ar fi Tensor Cores, devine mai mica, acest lucru nu face neaparat GPU mai rapid, deoarece principala problema pentru multiplicarea matricei este de a aduce memorie la nucleele tensorului, care este dictata de viteza si dimensiunea RAM de SRAM si GPU. RAM-ul GPU creste in continuare in viteza daca stivuim module de memorie in module cu latime de banda mare (HBM3+), dar acestea sunt prea scumpe de fabricat pentru aplicatii de consum. Principala modalitate de a imbunatati viteza bruta a GPU-urilor este utilizarea mai multa putere si mai multa racire, asa cum am vazut in seriile RTX 30s si 40s. Dar acest lucru nu poate dura mult timp.
Chipleturile, cum ar fi cele folosite de procesoarele AMD, sunt o alta cale simpla de urmat. AMD a invins Intel prin dezvoltarea de chipleturi CPU. Chipletele sunt cipuri mici care sunt fuzionate impreuna cu o retea de mare viteza pe cip. Va puteti gandi la ele ca la doua GPU-uri atat de apropiate fizic, incat aproape ca le puteti considera un singur GPU mare. Sunt mai ieftine de fabricat, dar mai dificil de combinat intr-un singur cip mare. Deci aveti nevoie de know-how si de conectivitate rapida intre chipleturi. AMD are multa experienta in designul chipleturilor. GPU-urile AMD de urmatoarea generatie vor fi modele cu chiplet, in timp ce NVIDIA nu are in prezent planuri publice pentru astfel de design. Acest lucru poate insemna ca urmatoarea generatie de GPU-uri AMD ar putea fi mai buna in ceea ce priveste costul/performanta in comparatie cu GPU-urile NVIDIA.
Cu toate acestea, principala crestere a performantei pentru GPU-uri este in prezent logica specializata. De exemplu, unitatile hardware de copiere asincrona din generatia Ampere (RTX 30 / A100 / RTX 40) sau extensia, Tensor Memory Accelerator (TMA), ambele reduc supraincarcarea memoriei de copiere din memoria globala lenta la memoria partajata rapida ( cache) prin hardware specializat si astfel fiecare fir poate face mai multe calcule. TMA reduce, de asemenea, supraincarcarea prin efectuarea de calcule automate ale indicilor de citire/scriere, ceea ce este deosebit de important pentru calculul pe 8 biti, unde exista elemente duble pentru aceeasi cantitate de memorie comparativ cu calculul pe 16 biti. Deci, logica hardware specializata poate accelera in continuare multiplicarea matricei.
Precizia de biti scazut este o alta cale simpla de urmat pentru cativa ani. Vom vedea adoptarea pe scara larga a inferentei si instruirii pe 8 biti in urmatoarele luni. Vom vedea o inferenta pe 4 biti pe scara larga in anul urmator. In prezent, tehnologia pentru antrenament pe 4 biti nu exista, dar cercetarea pare promitatoare si ma astept ca primul model FP4 Large Language (LLM) de inalta performanta cu performanta predictiva competitiva sa fie antrenat in 1-2 ani.
Trecerea la precizia de 2 biti pentru antrenament pare in prezent destul de imposibila, dar este o problema mult mai usoara decat micsorarea in continuare a tranzistorilor. Deci, progresul in hardware depinde in mare masura de software si algoritmi care fac posibila utilizarea caracteristicilor specializate oferite de hardware.
Probabil ca vom putea imbunatati in continuare combinatia de algoritmi + hardware pana in anul 2032, dar dupa aceea vom ajunge la sfarsitul imbunatatirilor GPU (asemanatoare cu smartphone-urile). Valul de imbunatatiri ale performantei dupa 2032 va veni din algoritmi de retea mai buni si hardware de masa. Nu este sigur daca GPU-urile pentru consumatori vor fi relevante in acest moment. S-ar putea sa aveti nevoie de un RTX 9090 pentru a rula Super HyperStableDiffusion Ultra Plus 9000 Extra sau OpenChatGPT 5.0, dar s-ar putea, de asemenea, ca unele companii sa ofere un API de inalta calitate, care este mai ieftin decat costul energiei electrice pentru un RTX 9090 si dvs. doriti sa utilizati un laptop + API pentru generarea de imagini si alte sarcini.
In general, cred ca investitia intr-un GPU capabil de 8 biti va fi o investitie foarte solida pentru urmatorii 9 ani. Imbunatatirile la 4 biti si 2 biti sunt probabil mici, iar alte caracteristici precum Sort Cores vor deveni relevante doar odata ce multiplicarea matriceala rara poate fi valorificata bine. Probabil ca vom vedea un alt fel de progres in 2-3 ani, care va ajunge in urmatorul GPU peste 4 ani, dar ramanem fara abur daca continuam sa ne bazam pe multiplicarea matricei. Acest lucru face ca investitiile in noi GPU sa dureze mai mult.
Intrebari si raspunsuri si conceptii gresite
Am nevoie de PCIe 4.0 sau PCIe 5.0?
In general, nu. PCIe 5.0 sau 4.0 este grozav daca aveti un cluster GPU. Este in regula daca aveti o masina GPU de 8x, dar in rest, nu aduce multe beneficii. Permite o paralelizare mai buna si un transfer de date putin mai rapid. Transferurile de date nu reprezinta un blocaj in nicio aplicatie. In viziunea computerizata, in conducta de transfer de date, stocarea datelor poate fi un blocaj, dar nu si transferul PCIe de la CPU la GPU. Deci, nu exista un motiv real pentru a obtine o configurare PCIe 5.0 sau 4.0 pentru majoritatea oamenilor. Beneficiile vor fi o paralelizare cu 1-7% mai buna intr-o configuratie cu 4 GPU.
Am nevoie de benzi PCIe 8x/16x?
La fel ca si cu PCIe 4.0 – in general, nu. Benzile PCIe sunt necesare pentru paralelizare si transferuri rapide de date, care sunt rareori un blocaj. Operarea GPU-urilor pe benzi de 4x este bine, mai ales daca aveti doar 2 GPU-uri. Pentru o configuratie cu 4 GPU, as prefera 8x benzi pe GPU, dar rularea lor pe 4x benzi va scadea probabil doar performanta cu aproximativ 5-10% daca paralelizati pe toate cele 4 GPU-uri.
Cum pot monta 4x RTX 4090 sau 3090 daca ocupa 3 sloturi PCIe fiecare?
Trebuie sa obtineti una dintre variantele cu doua sloturi sau puteti incerca sa le extindeti cu extensii PCIe. Pe langa spatiu, ar trebui sa va ganditi imediat la racire si la un alimentator adecvat.
Extensoarele PCIe ar putea rezolva, de asemenea, atat problemele de spatiu, cat si de racire, dar trebuie sa va asigurati ca aveti suficient spatiu in carcasa pentru a extinde GPU-urile. Asigurati-va ca extensiile PCIe sunt suficient de lungi!
Cum racesc 4x RTX 3090 sau 4x RTX 3080?
Vezi sectiunea anterioara.
Pot folosi mai multe GPU-uri de diferite tipuri de GPU?
Da, poti! Dar nu puteti paraleliza eficient intre GPU-uri de diferite tipuri, deoarece veti merge adesea la viteza celui mai lent GPU (date si paralelism complet fragmentat). Deci, diferite GPU-uri functioneaza bine, dar paralelizarea intre aceste GPU-uri va fi ineficienta, deoarece cel mai rapid GPU va astepta ca cel mai lent GPU sa ajunga la un punct de sincronizare (de obicei, actualizare cu gradient).
Ce este NVLink si este util?
In general, NVLink nu este util. NVLink este o interconectare de mare viteza intre GPU-uri. Este util daca aveti un cluster GPU cu +128 GPU-uri. In caz contrar, nu aduce aproape niciun beneficiu fata de transferurile standard PCIe.
Nu am destui bani, chiar si pentru cele mai ieftine GPU-uri pe care le recomandati. Ce pot face?
Cumparati cu siguranta GPU-uri folosite. Puteti cumpara un GPU mic si ieftin pentru prototipare si testare si apoi puteti rula pentru experimente complete in cloud, cum ar fi vast.ai sau Lambda Cloud. Acest lucru poate fi ieftin daca antrenati/reglati fin/inferentele pe modele mari doar din cand in cand si ati petrecut mai mult timp creand prototipuri pe modele mai mici.
Care este amprenta de carbon a GPU-urilor? Cum pot folosi GPU-urile fara a polua mediul?
Am construit un calculator de carbon pentru calcularea amprentei tale de carbon pentru mediul academic (carbon de la zboruri la conferinte + timpul GPU). Calculatorul poate fi folosit si pentru a calcula amprenta de carbon pura a GPU-ului. Veti descoperi ca GPU-urile produc mult, mult mai mult carbon decat zborurile internationale. Ca atare, ar trebui sa va asigurati ca aveti o sursa verde de energie daca nu doriti sa aveti o amprenta de carbon astronomica. Daca niciun furnizor de energie electrica din zona noastra nu ofera energie verde, cel mai bun mod este sa cumparati compensatii de carbon. Multi oameni sunt sceptici cu privire la compensarea emisiilor de carbon. Functioneaza? Sunt escrocherii?
Cred ca scepticismul doar doare in acest caz, pentru ca a nu face nimic ar fi mai daunator decat a risca probabilitatea de a fi inselat. Daca va faceti griji pentru escrocherii, investiti intr-un portofoliu de compensatii pentru a minimiza riscul.
Am lucrat la un proiect care a produs compensatii de carbon acum aproximativ zece ani. Compensatiile de carbon au fost generate de arderea metanului scurs din minele din China. Oficialii ONU au urmarit procesul si au cerut date digitale curate si inspectii fizice ale amplasamentului proiectului. In acest caz, compensatiile de carbon care au fost produse au fost foarte fiabile. Cred ca multe alte proiecte au standarde de calitate similare.
De ce am nevoie pentru a paraleliza intre doua masini?
Daca doriti sa fiti in siguranta, ar trebui sa obtineti placi de retea de cel putin +50 Gbits/s pentru a obtine viteze daca doriti sa paralelizati intre masini. Recomand sa aveti cel putin o configuratie EDR Infiniband, adica o placa de retea cu latime de banda de cel putin 50 GBit/s. Doua carduri EDR cu cablu costa aproximativ 500 USD pe eBay.
In unele cazuri, s-ar putea sa scapi cu Ethernet de 10 Gbit/s, dar acesta este de obicei cazul doar pentru retele speciale (anumite retele convolutionale) sau daca folosesti anumiti algoritmi (Microsoft DeepSpeed).
Caracteristicile de multiplicare a matricei rare sunt potrivite pentru matricele rare in general?
Nu pare asa. Deoarece granularitatea matricei rare trebuie sa aiba 2 elemente cu valoare zero, la fiecare 4 elemente, matricele rare trebuie sa fie destul de structurate. Ar putea fi posibila ajustarea usor a algoritmului, ceea ce implica combinarea a 4 valori intr-o reprezentare comprimata a 2 valori, dar asta inseamna, de asemenea, ca multiplicarea precisa a matricei rare nu este posibila cu GPU-urile Ampere.
Am nevoie de un procesor Intel pentru a alimenta o configurare multi-GPU?
Nu recomand procesoarele Intel decat daca utilizati foarte mult procesoarele in competitiile Kaggle (algebra liniara grea pe procesor). Chiar si pentru competitiile Kaggle, procesoarele AMD sunt inca grozave, totusi. Procesoarele AMD sunt mai ieftine si mai bune decat procesoarele Intel in general pentru invatare profunda. Pentru un GPU de 4x construit, procesorul meu preferat ar fi un Threadripper. Am construit zeci de sisteme la universitatea noastra cu Threadrippers si toate functioneaza excelent – inca nu exista plangeri. Pentru sistemele GPU 8x, as opta de obicei cu procesoare cu care furnizorul dvs. are experienta. Fiabilitatea CPU si PCIe/sistem este mai importanta in sistemele 8x decat performanta directa sau rentabilitatea directa.
Designul carcasei computerului conteaza pentru racire?
Nu. GPU-urile sunt de obicei perfect racite daca exista cel putin un mic decalaj intre GPU-uri. Designul carcasei va va oferi temperaturi cu 1-3 C mai bune, spatiul dintre GPU-uri va va oferi imbunatatiri cu 10-30 C. In concluzie, daca aveti spatiu intre GPU-uri, racirea nu conteaza. Daca nu aveti spatiu intre GPU-uri, aveti nevoie de designul potrivit de cooler (ventilator) sau de alta solutie (racire cu apa, extensii PCIe), dar in niciun caz, designul carcasei si ventilatoarele carcasei nu conteaza.
GPU-urile AMD + ROCm vor ajunge vreodata din urma cu GPU-urile NVIDIA + CUDA?
Nu in urmatorii 1-2 ani. Este o problema cu trei cai: Tensor Cores, software si comunitate.
GPU-urile AMD sunt grozave in ceea ce priveste siliciul pur: performanta excelenta FP16, latime de banda mare a memoriei. Cu toate acestea, lipsa lor de Tensor Cores sau echivalent face ca performanta lor de deep learning sa fie slaba in comparatie cu GPU-urile NVIDIA. Matematica cu precizie redusa nu o reduce. Fara aceasta caracteristica hardware, GPU-urile AMD nu vor fi niciodata competitive. Zvonurile arata ca un card de centru de date cu echivalentul Tensor Core este planificat pentru 2020, dar nu au aparut date noi de atunci. Doar a avea carduri pentru centre de date cu un echivalent Tensor Core ar insemna, de asemenea, ca putini si-ar putea permite astfel de GPU-uri AMD, ceea ce ar oferi NVIDIA un avantaj competitiv.
Sa presupunem ca AMD introduce in viitor o caracteristica hardware asemanatoare Tensor-Core. Apoi multi oameni ar spune: „Dar nu exista niciun software care sa functioneze pentru GPU-urile AMD! Cum ar trebui sa le folosesc?” Aceasta este in mare parte o conceptie gresita. Software-ul AMD prin ROCm a parcurs un drum lung, iar suportul prin PyTorch este excelent. Desi nu am vazut multe rapoarte de experienta pentru GPU-urile AMD + PyTorch, toate caracteristicile software sunt integrate. Se pare, daca alegeti orice retea, veti fi bine sa o rulati pe GPU-uri AMD. Deci, aici AMD a parcurs un drum lung, iar aceasta problema este mai mult sau mai putin rezolvata.
Totusi, daca rezolvi software-ul si lipsa Tensor Cores, AMD mai are o problema: lipsa comunitatii. Daca aveti o problema cu GPU-urile NVIDIA, puteti gasi problema pe Google si gasiti o solutie. Acest lucru creeaza multa incredere in GPU-urile NVIDIA. Aveti infrastructura care faciliteaza utilizarea GPU-urilor NVIDIA (orice cadru de invatare profunda functioneaza, orice problema stiintifica este bine sustinuta). Aveti hack-urile si trucurile care fac utilizarea GPU-urilor NVIDIA o usoara (de exemplu, apex). Puteti gasi experti in GPU-uri NVIDIA si programare in orice colt, in timp ce eu cunosteam mult mai putin experti in GPU AMD.
In aspectul comunitatii, AMD seamana putin cu Julia vs Python. Julia are mult potential si multi ar spune, si pe buna dreptate, ca este limbajul de programare superior pentru calculul stiintific. Cu toate acestea, Julia abia este folosita in comparatie cu Python. Acest lucru se datoreaza faptului ca comunitatea Python este foarte puternica. Numpy, SciPy, Pandas sunt pachete software puternice in jurul carora se aduna un numar mare de oameni. Aceasta este foarte asemanatoare cu problema NVIDIA vs AMD.
Astfel, este probabil ca AMD sa nu ajunga din urma pana cand nu este introdus echivalentul Tensor Core (1/2 pana la 1 an?) si se construieste o comunitate puternica in jurul ROCm (2 ani?). AMD va smulge intotdeauna o parte din cota de piata in anumite subgrupe (de exemplu, minerit de criptomonede, centre de date). Totusi, in deep learning, NVIDIA isi va pastra probabil monopolul cel putin inca cativa ani.
Cand este mai bine sa folositi cloud-ul fata de un desktop/server GPU dedicat?
Regula generala: daca va asteptati sa faceti deep learning pentru mai mult de un an, este mai ieftin sa obtineti un GPU desktop. In caz contrar, instantele cloud sunt de preferat, cu exceptia cazului in care aveti abilitati extinse de cloud computing si doriti beneficiile cresterii si reducerii numarului de GPU-uri dupa bunul plac.
Cifrele din paragrafele urmatoare se vor schimba, dar serveste ca un scenariu care va ajuta sa intelegeti costurile brute. Puteti folosi matematica similara pentru a determina daca GPU-urile cloud sunt cea mai buna solutie pentru dvs.
Pentru momentul exact in care un GPU in cloud este mai scump decat un desktop depinde in mare masura de serviciul pe care il utilizati si cel mai bine este sa faceti un pic de matematica singur. Mai jos fac un exemplu de calcul pentru o instanta spot AWS V100 cu 1x V100 si o compar cu pretul unui desktop cu un singur RTX 3090 (performanta similara). Desktop-ul cu RTX 3090 costa 2.200 USD (2-GPU barebone + RTX 3090). In plus, presupunand ca va aflati in SUA, exista o suma suplimentara de 0,12 USD per kWh pentru electricitate. Aceasta se compara cu 2,14 USD pe ora pentru instanta la cerere AWS.
Cu o utilizare de 15% pe an, desktopul foloseste:
(350 W (GPU) + 100 W (CPU))*0,15 (utilizare) * 24 ore * 365 zile = 591 kWh pe an
Deci 591 kWh de electricitate pe an, adica 71 USD in plus.
Pragul de rentabilitate pentru un desktop fata de o instanta cloud cu o utilizare de 15% (utilizati instanta cloud 15% din timp in timpul zilei), ar fi de aproximativ 300 de zile (2.311 USD fata de 2.270 USD):
2,14 USD/h * 0,15 (utilizare) * 24 de ore * 300 de zile = 2.311 USD
Deci, daca va asteptati sa rulati modele de invatare profunda dupa 300 de zile, este mai bine sa cumparati un desktop in loc sa utilizati instante la cerere AWS.
Puteti face calcule similare pentru orice serviciu cloud pentru a lua decizia daca alegeti un serviciu cloud sau un desktop.
Ratele comune de utilizare sunt urmatoarele:
- Desktop personal al doctoranzilor: < 15%
- Cluster GPU slurm student doctorand: > 35%
- Cluster de cercetare slurm la nivel de companie: > 60%
In general, ratele de utilizare sunt mai mici pentru profesiile in care gandirea la idei de ultima ora este mai importanta decat dezvoltarea de produse practice. Unele zone au rate de utilizare scazute (cercetare de interpretabilitate), in timp ce alte zone au rate mult mai mari (traducere automata, modelare lingvistica). In general, utilizarea masinilor personale este aproape intotdeauna supraestimata. De obicei, majoritatea sistemelor personale au o rata de utilizare intre 5-10%. Acesta este motivul pentru care as recomanda cu caldura clusterele de GPU slurm pentru grupuri de cercetare si companii in loc de masini GPU desktop individuale.


")



 cu protecție la foc.")













{kind=link}